BerryDB Architecture
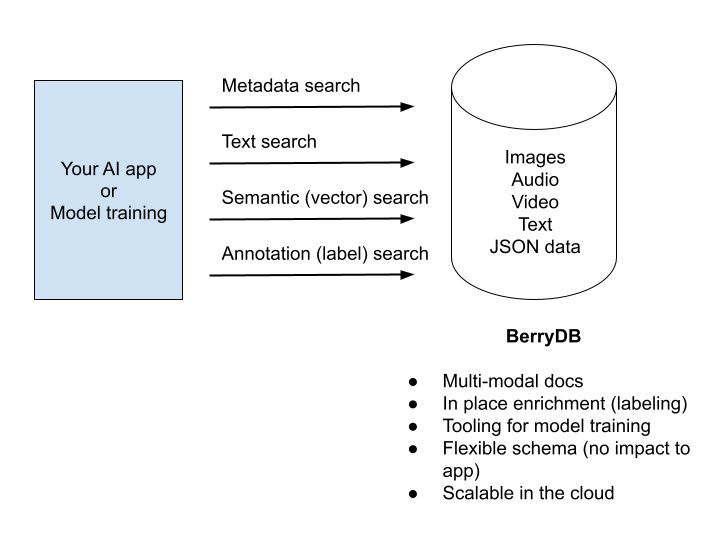
BerryDB is a JSON native database that supports unstructured data. It provides the capability to store, process, label and search through images, audio, video, text and JSON documents. It also provides utilities to convert PDF, PPT and other documents to text or images so they can be managed inside BerryDB. It provides an integrated search and indexing capability so users can search through all kinds of data without requiring different backends.
- Metadata index - For searching through fields in schema. No need for a separate database
- Full text index - For searching through text, no need for elastic search
- Vector index - For semantic search and creating embeddings for LLMs. No need for a separate vector db
- Label studio - For labeling unstructured data. No need for a separate labeling system
BerryDB stores the JSON structures as is without requiring translation to other formats. It understands the JSON format natively for indexing, search, labeling and other operations. It is an in-memory database that provides eventual persistence to disk. As a result of these foundational principles, it has super fast performance on reads and writes compared to other databases (compared to MongoDB or MySQL). In one benchmark test, involving 10M JSON reads and 10 M JSON write operations BerryDB was 5x faster compared to MongoDB.
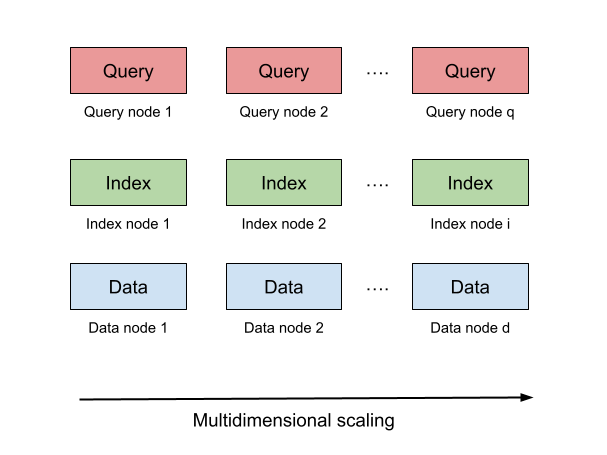
With the modern data access patterns it is clear that users need to have separate scaling considerations for data, index and queries. For example, Google's web index got bigger than the size of its web data as early as 2006. So, combining data, index and queries into a single scaling strategy is not going to work anymore. BerryDB is designed ground up to support multi-dimensional scaling in the cloud. It can horizontally scale database services independent of each other - data, index and query services.