Everything Starts With Knowledge and Annotations
We build the knowledge and annotation infrastructure on your data.
You build the future AI software.
Governable, Modifiable, Queryable, Automated Knowledge Graphs for Structured Data and Unstructured Data (Docs, PDF, Images, Audio & Video)
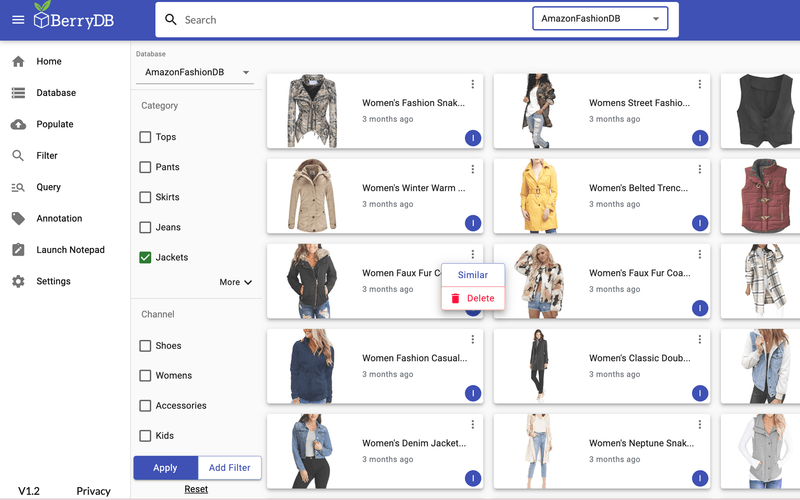
We build the knowledge and annotation infrastructure on your data.
You build the future AI software.
It is the meaning and semantic information derived from the raw data such that AI agents can understand, reason and act.
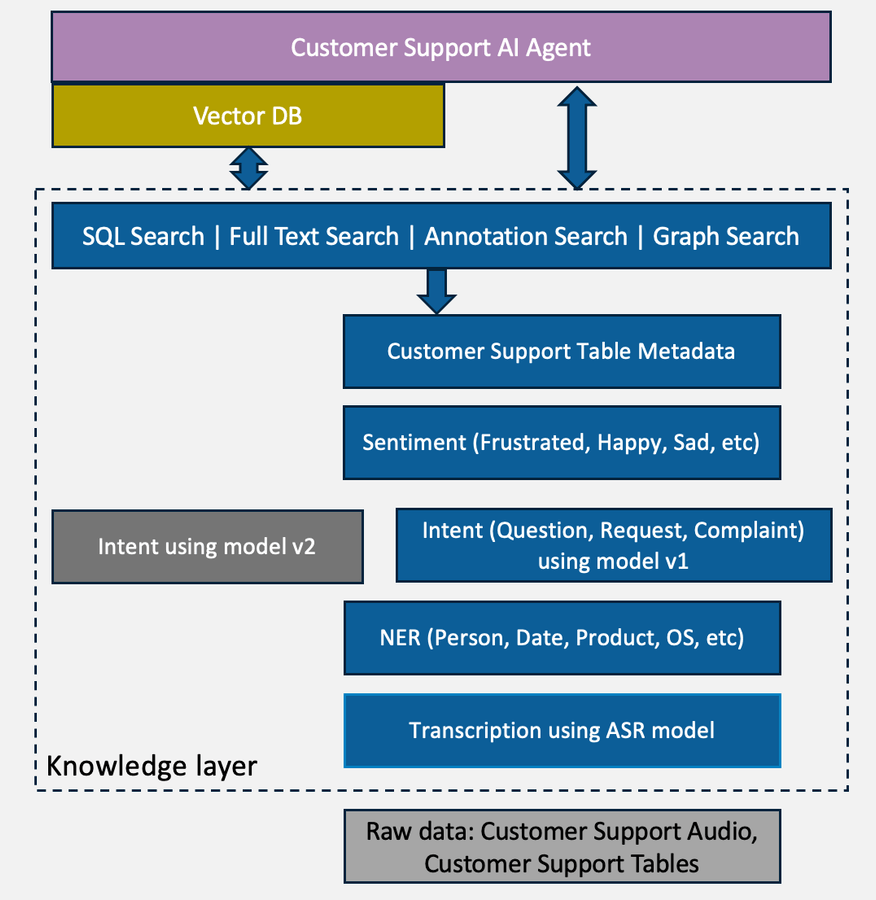
As AI agents start writing code and make decisions, a governable knowledge layer is not optional.
Its the foundation for control, intellectual property and long-term competitive advantage
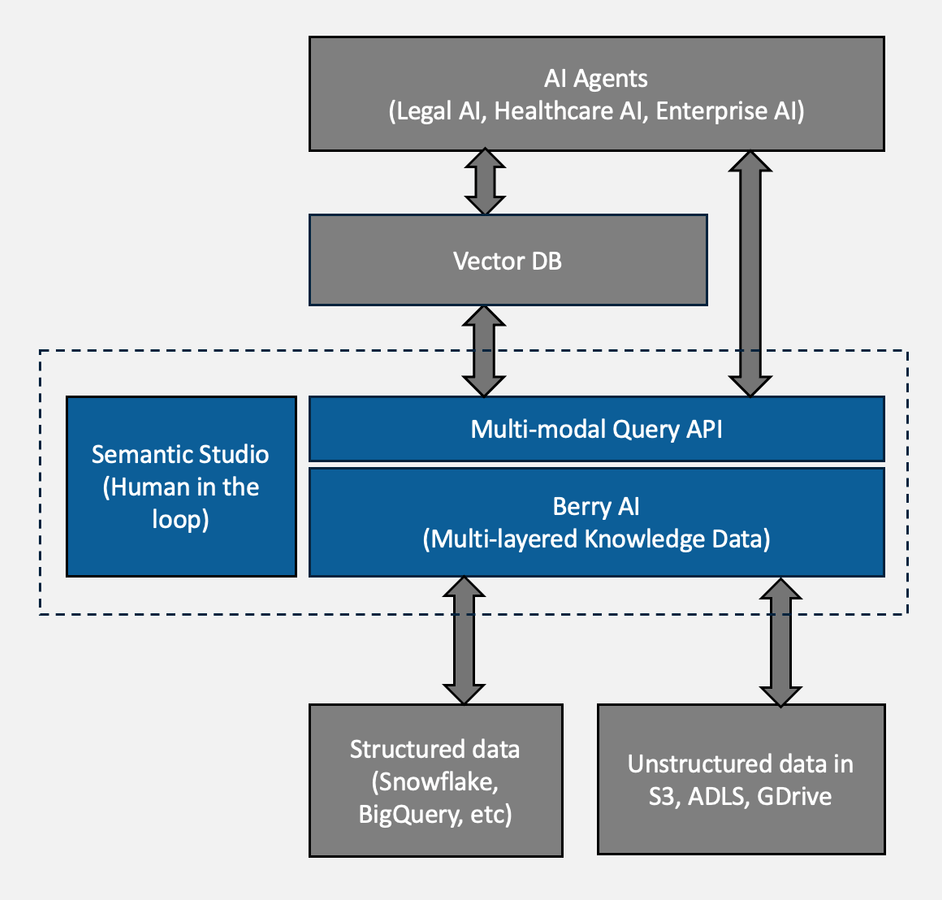
It is the first system purpose-built for building and managing knowledge graphs on structured and unstructured data. The missing layer between raw data lake and AI agents & vector DB
Embedded semantic studio with built-in AI models to process unstructured data
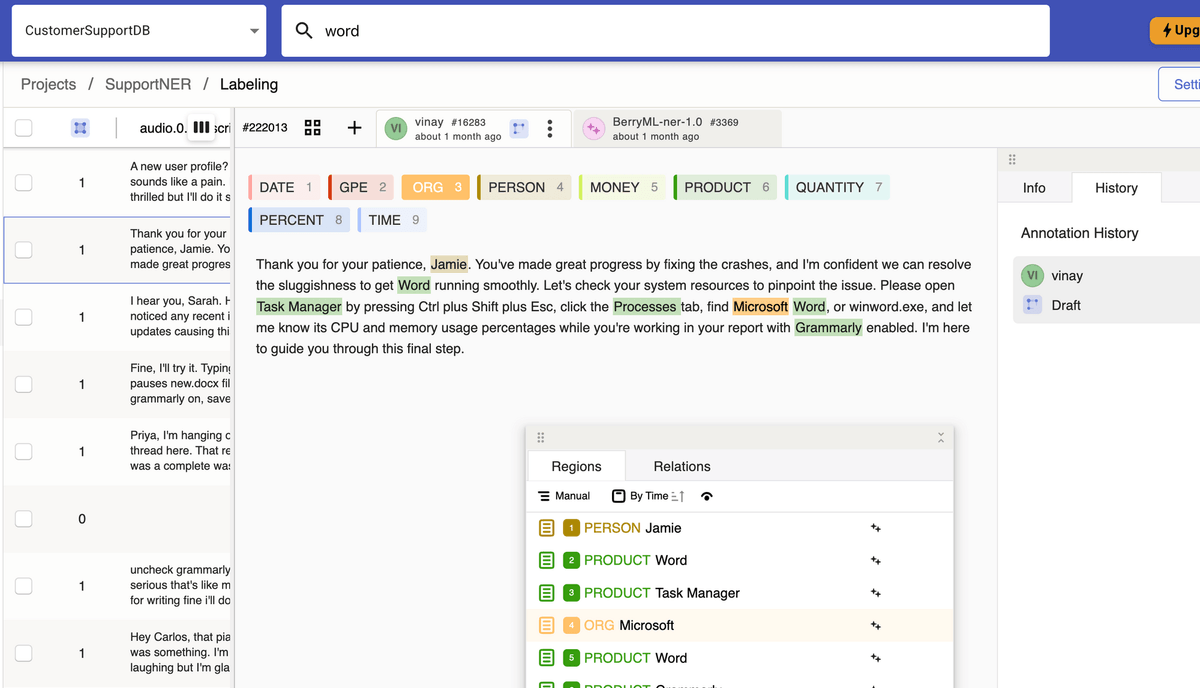
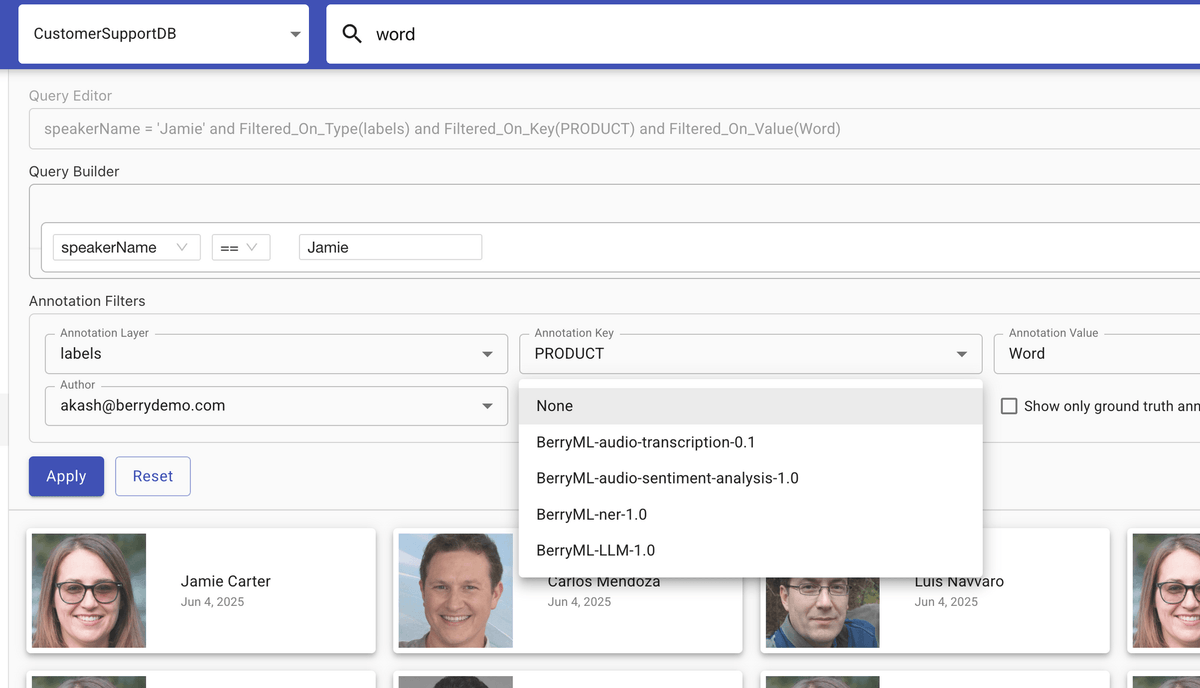
Integrates metadata search (SQL), full-text search, annotation search, and graph search in a single system. Users have the flexibility to combine these search queries as needed

Powerful API to ingest, enrich and search through knowledge graphs: See https://docs.berrydb.io/python-sdk/
Product overview video
Contact us or sign up for 30 day free trial access