Getting started with FHIR in BerryDB is easy! A simple three step process gets all your FHIR data populated, cataloged and ready for search. The purpose of this article is to describe the high level process and the core features.
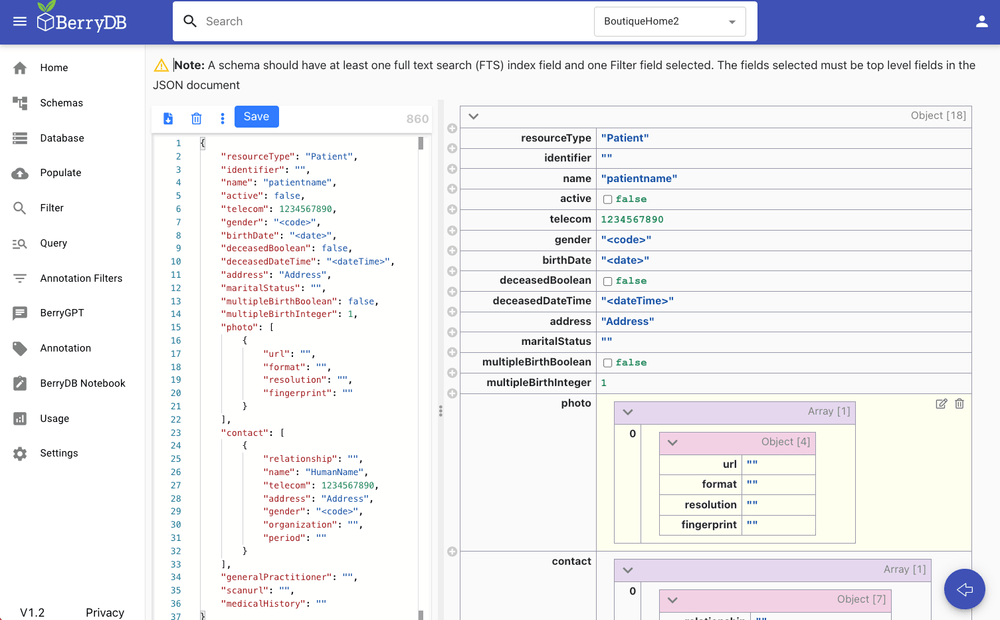
Step 0: Create an FHIR resource schema. BerryDB provides a FHIR schema editor as show below that supports image, audio, video, text, array and nested data types. Create the right schema required for the resource - the example below shows "FHIR Patient" resource. BerryDB supports schema evolution. You can always add custoom fields to your FHIR resource and change your schema without impacting your app or interoperability.
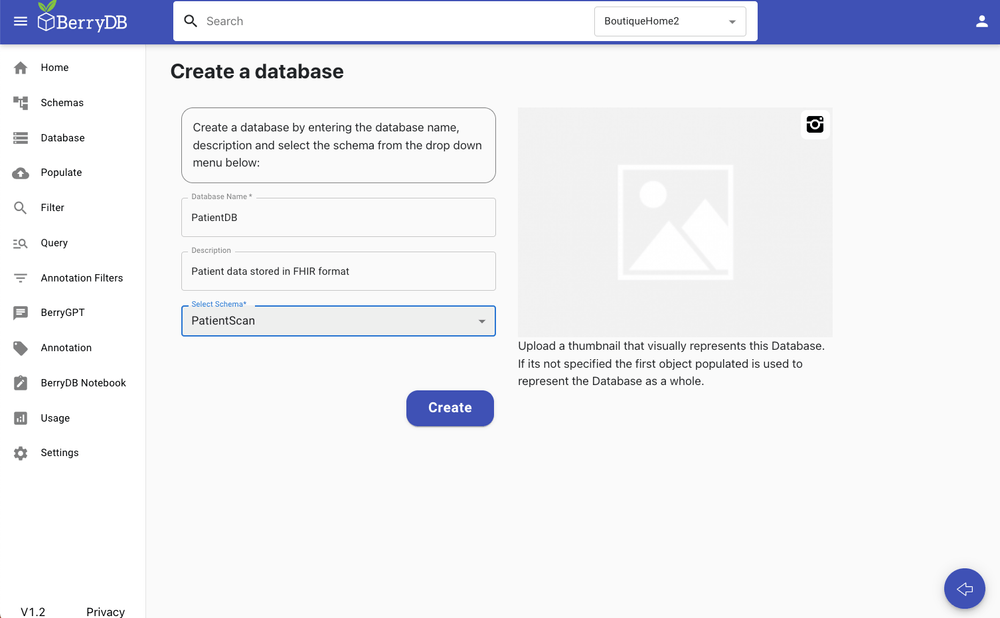
Step 1: Create a database, give it a name and description.
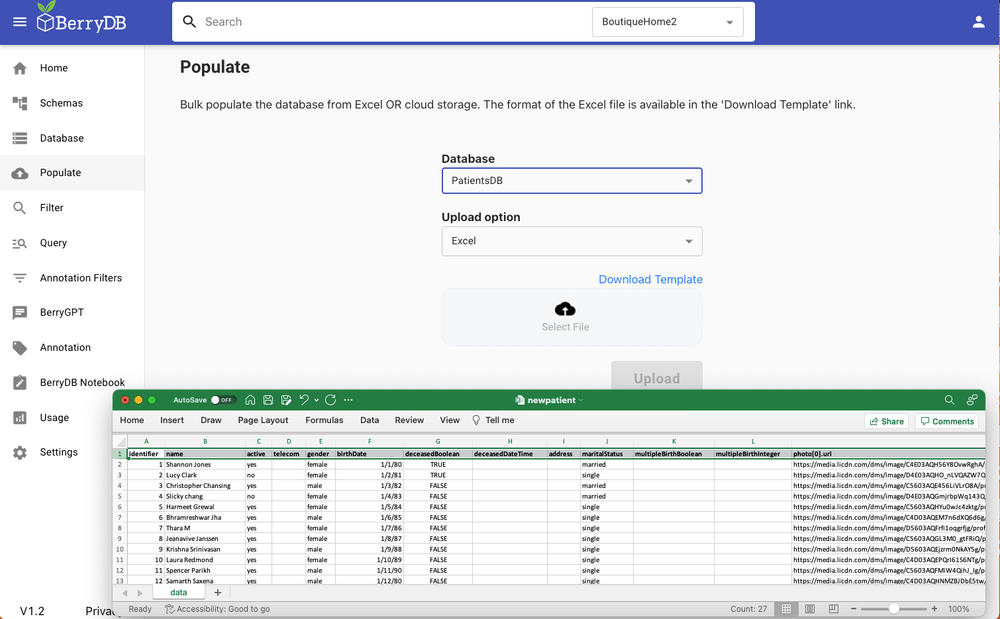
Step 2: Populate the FHIR database. BerryDB supports bulk upload using Excel. Select the database from the drop down and download the excel template. The excel template would have the right header fields corresponding to the schema including nested objects and arrays. Fill in the data in the excel file in the appropriate columns. BerryDB supports sparse datasets. You can leave empty columns or rows in case of missing data. Once you click upload, BerryDB automatically maps the data items into the schema, indexes all the fields appropriately, creates the filters needed and makes the data ready for search.
Once the data is populated, use the following options to enrich, seach and retrieve the datasets:
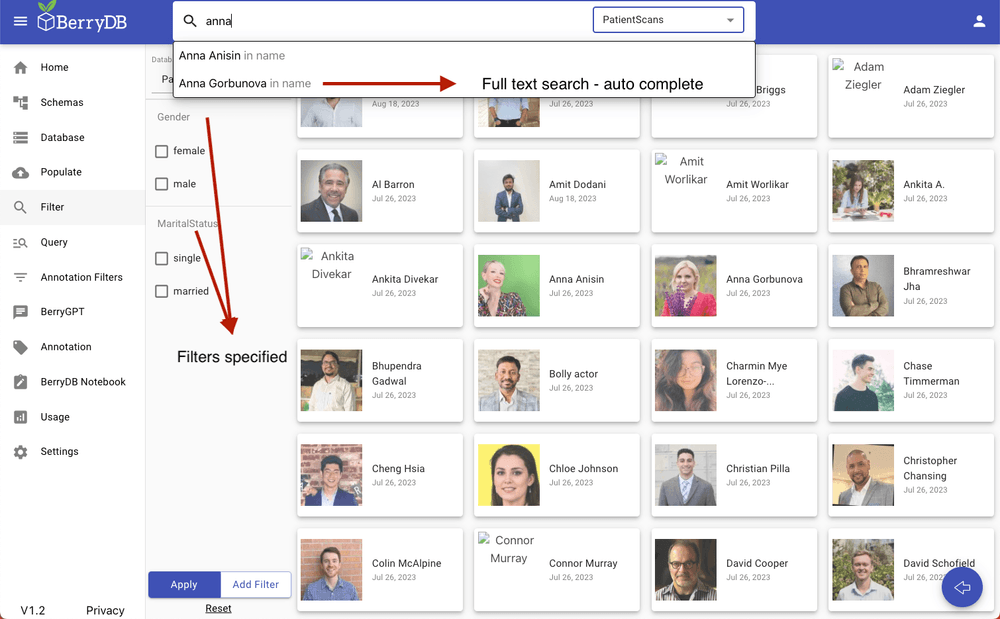
Option 1: Visually filter the data. BerryDB automatically creates a visual filter page - use this to slice and dice the data.
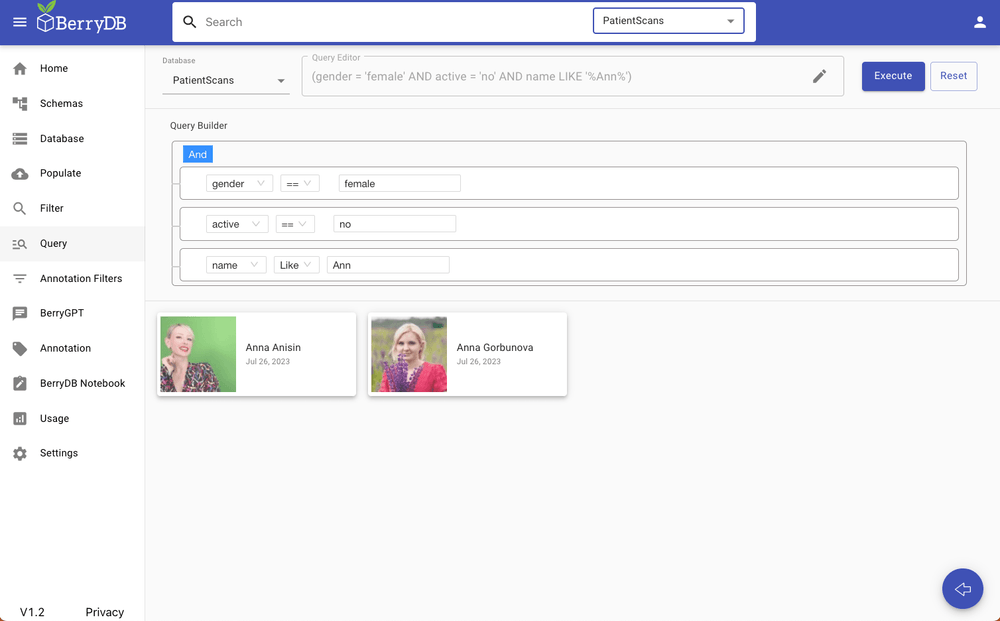
Option 2: Query the database using SQL builder
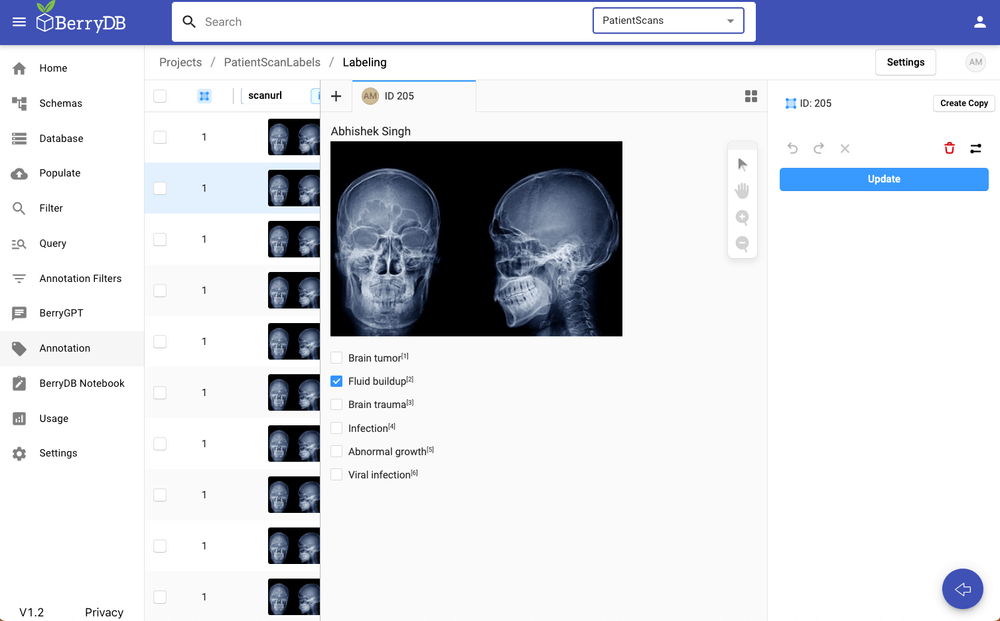
Option 3: Enrich the dataset using in-built annotation studio. Users can build an annotation widget for the FHIR data with no coding and make it available for the annotaters. The resulting labels are automatically added to the data model and indexed for search. In this example, an image classification annotation widget is used to annotate a CT scan.
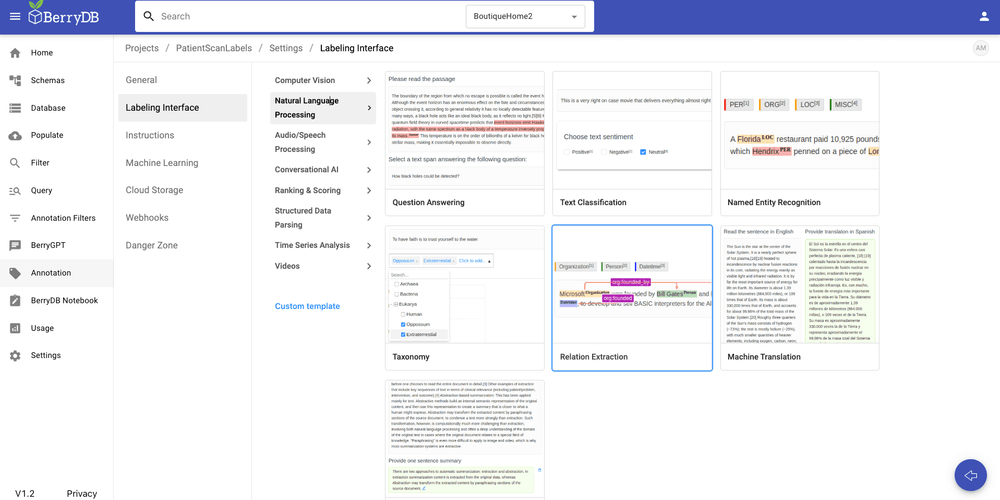
BerryDB supports a large number of annotation widgets. For example the following are supported
- Computer vision annotations
- Semantic segmentation
- Object dectection bounding box
- Image classification and more
- NLP annotations
- Taxonomy
- Named entity recognition
- Text classification and more
- Audio and speech recognition
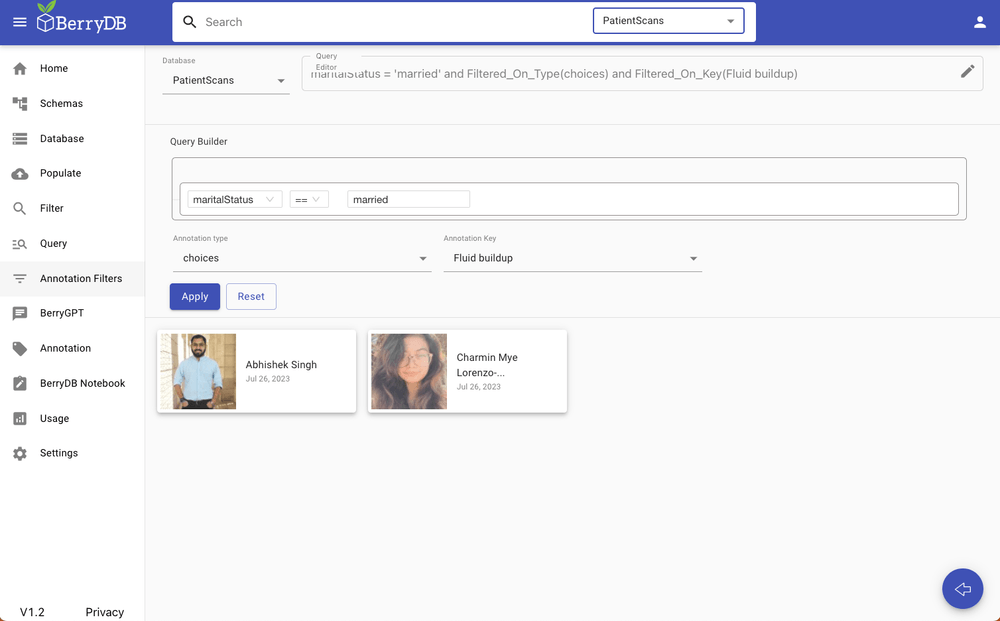
Option 4: Annotation search. You can search through labeled data using annotation search option
Option 5: BerryDB API. BerryDB provides an API to access to the data. Users can access the data from a notebook. Here's a cookbook example - this is a foundational notebook that demonstrates how to get started with BerryDB API. It shows how to connect to BerryDB, access your database, read and write records
https://colab.research.google.com/drive/1ST2uoDhH0xk02yOONpxmM0Ct2Y65ODVv
Option 6: Chat interface to BerryDB. BerryDB has a built-in vector database. It embeds all the records in the document in a vector store. As a result, users can use plain English language to search through text and unstructured data.
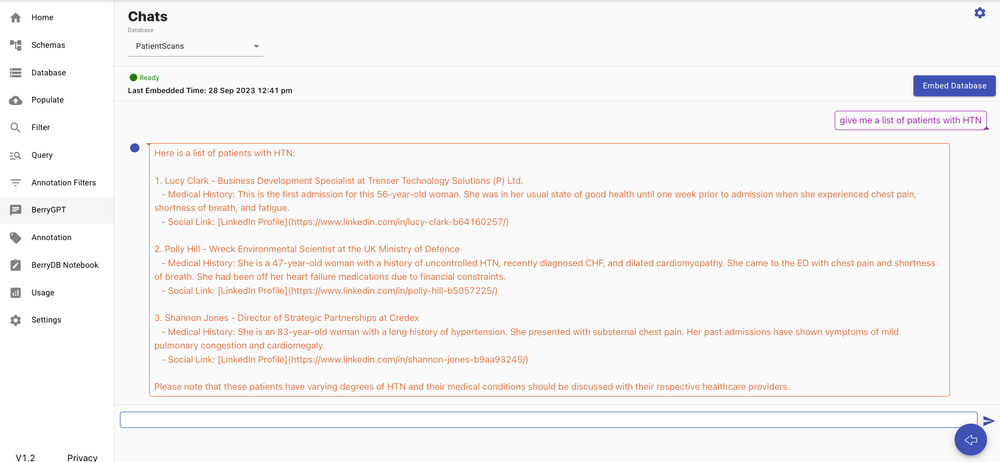


Option 7: Chat interface to BerryDB database using API.
Here's an example notebook called ShopGPT that provides a chat interface to a BerryDB database containing ecommerce data (Amazon fashion data). It loads the ecommerce catalog and annotations as embeddings into an LLM model (in this case we use OpenAI GPT). Provides a conversational UI for a shopper to search through ecommerce catalog.
https://colab.research.google.com/drive/1yS8tam718A6WJj7Hh9x9F6uoIKWJL6rP